- تجارت CFD طلا: راهنمای مبتدی
- Binance در مقابل Bitstamp: آیا استفاده از آنها قانونی است؟
- 2 ETF Crypto برای استفاده از نوسانات رو به رشد بیت کوین
- در واقع ... یک سفارش محدود چیست؟
- ارزیابی درآمد املاک
- معیار
- استراتژی ویژه معاملات بورس تهران
- Crypto Market Monitor - 14 دسامبر 2022
- بهترین مکان برای دیدن شکوفه های گیلاس در اطراف ایالات متحده در این بهار
- از دست دادن توقف در فارکس چیست؟

آخرین مطالب
امکانات وب


FITCSVM برای طبقه بندی یک طبقه و دو طبقه (باینری) در یک مجموعه داده پیش بینی کننده کم بعدی یا متوسط ، قطار یا یک مدل دستگاه بردار پشتیبانی (SVM) را برای طبقه بندی یک طبقه و دو طبقه (باینری) ارائه می دهد. FITCSVM از نقشه برداری از داده های پیش بینی کننده با استفاده از توابع هسته پشتیبانی می کند و از حداقل بهینه سازی پی در پی (SMO) ، الگوریتم داده تک تک تک (ISDA) یا L 1 به حداقل رساندن حاشیه نرم از طریق برنامه نویسی درجه دوم برای به حداقل رساندن عملکرد هدف پشتیبانی می کند.
برای آموزش یک مدل SVM خطی برای طبقه بندی باینری در یک مجموعه داده با ابعاد بالا ، یعنی یک مجموعه داده که شامل بسیاری از متغیرهای پیش بینی کننده است ، به جای آن از FitClinear استفاده کنید.
برای یادگیری چند طبقه با مدلهای SVM باینری ترکیبی ، از کدهای خروجی اصلاح خطا (ECOC) استفاده کنید. برای اطلاعات بیشتر ، به FitCecoc مراجعه کنید.
برای آموزش یک مدل رگرسیون SVM ، به FITRSVM برای مجموعه داده های پیش بینی کننده کم بعدی و متوسط ، یا Fitrlinear برای مجموعه داده های با ابعاد بالا مراجعه کنید.
MDL = FITCSVM (TBL ، ResponsionVaame) طبقه بندی کننده دستگاه بردار پشتیبانی (SVM) MDL را با استفاده از داده های نمونه موجود در جدول TBL آموزش می دهد. ResponseVaame نام متغیر در TBL است که شامل برچسب های کلاس برای طبقه بندی یک کلاس یا دو طبقه است.
اگر متغیر برچسب کلاس فقط شامل یک کلاس باشد (به عنوان مثال ، یک بردار از آن ها) ، FITCSVM یک مدل را برای طبقه بندی یک طبقه آموزش می دهد. در غیر این صورت ، عملکرد یک مدل را برای طبقه بندی دو طبقه آموزش می دهد.
MDL = FITCSVM (TBL ، فرمول) یک طبقه بندی کننده SVM را که با استفاده از داده های نمونه موجود در جدول TBL آموزش داده می شود ، باز می گرداند. فرمول یک مدل توضیحی از پاسخ و زیر مجموعه ای از متغیرهای پیش بینی کننده در TBL است که برای متناسب بودن MDL استفاده می شود.
MDL = FITCSVM (TBL ، Y) یک طبقه بندی کننده SVM را که با استفاده از متغیرهای پیش بینی کننده در جدول TBL و برچسب های کلاس در وکتور y آموزش داده می شود ، برمی گرداند.
MDL = FITCSVM (X ، Y) یک طبقه بندی SVM را که با استفاده از پیش بینی کننده ها در ماتریس X و برچسب های کلاس در وکتور Y برای طبقه بندی یک کلاس یا دو طبقه آموزش داده می شود ، برمی گرداند.
MDL = FITCSVM (___ ، نام ، مقدار) علاوه بر آرگومان های ورودی در نحوهای قبلی ، گزینه ها را با استفاده از یک یا چند آرگومان با ارزش نام مشخص می کند. به عنوان مثال ، می توانید نوع اعتبارسنجی متقابل ، هزینه برای طبقه بندی نادرست و نوع عملکرد تبدیل نمره را مشخص کنید.
مثال ها
طبقه بندی کننده SVM را آموزش دهید
مجموعه داده های عنبیه فیشر را بارگیری کنید. طول و عرض سپال و تمام عنبیه های مشاهده شده Setosa را بردارید.
بارماهیچهinds =~strcmp (گونه ،'setosa') ؛x = اندازه گیری (inds ، 3: 4) ؛y = گونه (inds) ؛
با استفاده از مجموعه داده های پردازش شده ، یک طبقه بندی کننده SVM را آموزش دهید.
svmmodel = fitcsvm (x ، y)
SVMMODEL = طبقه بندی شده پاسخ پاسخ: 'y' cartorypredictors: [] کلاس های کلاس: امتیازات: "هیچ یک" Numobservations: 100 alpha: [24x1 Double] Bias: -14. 4149 Keelparameters: [1x1] Boxconstintraints: [100x1 Double Double] Converginfo:IssupportVector: [100x1 منطقی] حل کننده: خواص "SMO" ، روش ها
SVMMODEL یک طبقه بندی کننده طبقه بندی شده طبقه بندی شده است. خصوصیات SVMMODEL را نمایش دهید. به عنوان مثال ، برای تعیین ترتیب کلاس ، از نماد نقطه استفاده کنید.
classorder = svmmodel. classnames
classorder =سلول 2x1
کلاس اول ("Versicolor") کلاس منفی است و دومین ("Virginica") کلاس مثبت است. می توانید با استفاده از آرگومان جفت ارزش نام "کلاس" ، سفارش کلاس را در حین آموزش تغییر دهید.
نمودار پراکندگی داده ها را ترسیم کرده و بردارهای پشتیبانی را دایره کنید.
sv = svmmodel. supportvectors ؛شکل gscatter (x (: ، 1) ، x (: ، 2) ، y) نگه داریدonطرح (SV (: ، 1) ، SV (: ، 2) ،'ko','Markersize'، 10) افسانه ("Versicolor","ویرجینیکا","بردار پشتیبانی"))از روی
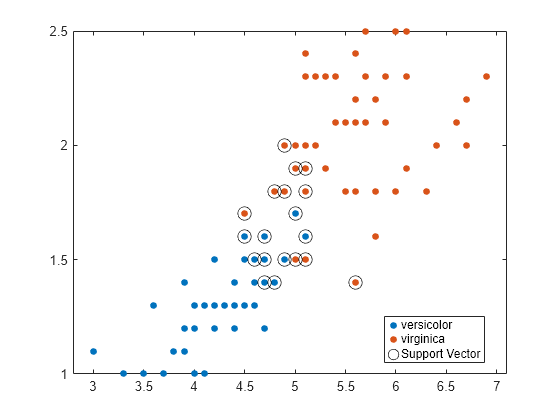
بردارهای پشتیبانی مشاهداتی هستند که در مرزهای تخمین زده شده آنها یا فراتر از آن اتفاق می افتد.
با تنظیم محدودیت جعبه در حین آموزش با استفاده از آرگومان جفت ارزش نام "BoxConstraint" می توانید مرزها (و بنابراین تعداد بردارهای پشتیبانی) را تنظیم کنید.
خطوط تصمیم گیری و خطوط حاشیه برای طبقه بندی SVM دو طبقه
این مثال نشان می دهد که چگونه می توان مرز تصمیم و خطوط حاشیه یک طبقه بندی کننده SVM دو طبقه (باینری) را با دو متغیر پیش بینی کننده ترسیم کرد.
مجموعه داده های عنبیه فیشر را بارگیری کنید. تمام گونه های Iris Versicolor (فقط گونه های Setosa و Virginica را ترک می کنند) را حذف کنید و فقط اندازه گیری طول و عرض آن را حفظ کنید.
بارماهیچه؛inds =~strcmp (گونه ،"Versicolor") ؛x = اندازه گیری (inds ، 1: 2) ؛s = گونه (inds) ؛
یک طبقه بندی کننده SVM هسته خطی را آموزش دهید.
svmmodel = fitcsvm (x ، s) ؛
SVMMODEL یک طبقه بندی کننده طبقه بندی شده طبقه بندی شده است ، که خصوصیات آن شامل بردارهای پشتیبانی ، ضرایب پیش بینی خطی و اصطلاح تعصب است.
sv = svmmodel. supportvectors ؛٪ بردارهای پشتیبانیبتا = svmmodel. beta ؛ضرایب پیش بینی خطیb = svmmodel. bias ؛اصطلاح تعصب
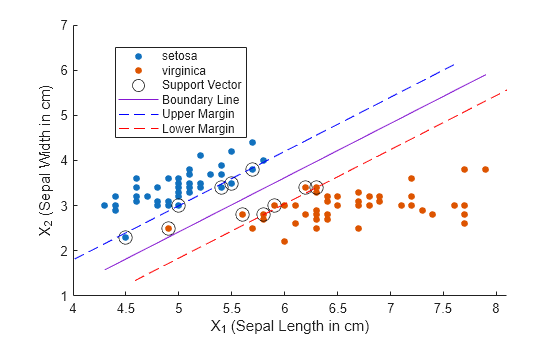
نمودار پراکندگی داده ها را ترسیم کنید و بردارهای پشتیبانی را دایره کنید. بردارهای پشتیبانی مشاهداتی هستند که در مرزهای تخمین زده شده آنها یا فراتر از آن اتفاق می افتد.
نگه داشتنongscatter (x (: ، 1) ، x (: ، 2) ، s) طرح (sv (: ، 1) ، sv (: ، 2) ،'ko','Markersize'، 10)
بهترین پلانج جداکننده برای طبقه بندی کننده SVMMODEL یک خط مستقیم است که توسط β 1 x 1 + β 2 x 2 + b = 0 مشخص شده است. مرز تصمیم گیری بین دو گونه را به عنوان یک خط جامد ترسیم کنید.
x1 = linspace (min (x (: ، 1)) ، حداکثر (x (: ، 1)) ، 100) ؛x2 = -(بتا (1)/بتا (2)*x1) -b/بتا (2) ؛طرح (x1 ، x2 ،'-')ضرایب پیش بینی کننده خطی β وکتوری را تعریف می کند که به مرز تصمیم گیری متعامد است. حداکثر عرض حاشیه 2 ||β ‖ - 1 (برای اطلاعات بیشتر ، به ماشین های بردار پشتیبانی برای طبقه بندی باینری مراجعه کنید). حداکثر مرزهای حاشیه را به عنوان خطوط متراکم ترسیم کنید. محورها را برچسب بزنید و یک افسانه اضافه کنید.
m = 1/sqrt (بتا (1)^2 + بتا (2)^2) ؛٪ حاشیه نیمه عرضx1margin_low = x1+beta (1)*m^2 ؛x2margin_low = x2+beta (2)*m^2 ؛x1margin_high = x1-beta (1)*m^2 ؛x2margin_high = x2-beta (2)*m^2 ؛طرح (x1margin_high ، x2margin_high ،'B--') طرح (x1margin_low ، x2margin_low ،'r--') xlabel ('x_1 (طول سپاه در سانتی متر)') ylabel ('x_2 (عرض سپال در سانتی متر)') افسانه('setosa',"ویرجینیکا","بردار پشتیبانی", . "خط مرزی","حاشیه بالایی","حاشیه پایین"))از روی
طبقه بندی کننده SVM را قطار و متقاطع کنید
مجموعه داده های یونوسفر را بارگیری کنید.
باریون کرهg (1) ؛٪ برای تکرارپذیری
با استفاده از هسته پایه شعاعی ، طبقه بندی کننده SVM را آموزش دهید. بگذارید نرم افزار مقدار مقیاس را برای عملکرد هسته پیدا کند. پیش بینی کننده ها را استاندارد کنید.
svmmodel = fitcsvm (x ، y ،"استاندارد"،درست است، واقعی،'Keelfction','RBF',. 'Keelscale','خودکار');
SVMMODEL یک طبقه بندی کننده طبقه بندی شده طبقه بندی شده است.
طبقه بندی کننده SVM را متقاطع کنید. به طور پیش فرض ، این نرم افزار از اعتبار سنجی متقاطع 10 برابر استفاده می کند.
cvsvmmodel = crossval (svmmodel) ؛
CVSVMMODEL یک طبقه بندی طبقه بندی شده طبقه بندی شده است.
نرخ نادرست طبقه بندی خارج از نمونه را تخمین بزنید.
classloss = kfoldloss (cvsvmmodel)
Classloss = 0. 0484
میزان تعمیم تقریباً 5 ٪ است.
با استفاده از SVM و یادگیری یک طبقه ، Outliers را تشخیص دهید
با اختصاص همه عنبیه به همان کلاس ، داده های عنبیه فیشر را اصلاح کنید. قسمتهای خارج از خانه را در مجموعه داده های اصلاح شده تشخیص دهید و نسبت مورد انتظار مشاهدات خارج از کشور را تأیید کنید.
مجموعه داده های عنبیه فیشر را بارگیری کنید. طول و عرض گلبرگ را بردارید. با تمام عنبیه ها که از همان کلاس آمده است رفتار کنید.
بارماهیچهx = اندازه گیری (: ، 1: 2) ؛y = موارد (اندازه (x ، 1) ، 1) ؛با استفاده از مجموعه داده های اصلاح شده ، یک طبقه بندی کننده SVM را آموزش دهید. فرض کنید که 5 ٪ از مشاهدات خارج از کشور هستند. پیش بینی کننده ها را استاندارد کنید.
g (1) ؛svmmodel = fitcsvm (x ، y ،'Keelscale','خودکار',"استاندارد"،درست است، واقعی،. 'Outlierfraction'، 0. 05) ؛
SVMMODEL یک طبقه بندی کننده طبقه بندی شده طبقه بندی شده است. به طور پیش فرض ، این نرم افزار از هسته گاوسی برای یادگیری یک طبقه استفاده می کند.
مشاهدات و مرز تصمیم گیری را ترسیم کنید. بردارهای پشتیبانی و مسافت های بالقوه را پرچم گذاری کنید.
svind = svmmodel. issupportvector ؛H = 0. 02 ؛اندازه گام شبکه مش[x1 ، x2] = meshgrid (min (x (: ، 1)): h: max (x (: ، 1)) ،.min (x (: ، 2)): h: max (x (: ، 2))) ؛[~، امتیاز] = پیش بینی (svmmodel ، [x1 (:) ، x2 (:)]) ؛SCOREGRID = تغییر شکل (نمره ، اندازه (x1،1) ، اندازه (x2،2)) ؛نمودار شکل (x (: ، 1) ، x (: ، 2) ،'k.'))onطرح (x (svind ، 1) ، x (svind ، 2) ،'ro','Markersize'، 10) کانتور (x1 ، x2 ، ScoreGrid) Colorbar ؛عنوان('') xlabel ("طول سپاه (سانتی متر)") ylabel ('عرض سپال (سانتی متر)') افسانه("مشاهده","بردار پشتیبانی"))از روی

مرز جدا کننده قسمتهای دور از بقیه داده ها در جایی اتفاق می افتد که مقدار کانتور 0 باشد.
تأیید کنید که کسری از مشاهدات با نمرات منفی در داده های معتبر متقاطع نزدیک به 5 ٪ است.
cvsvmmodel = crossval (svmmodel) ؛[~، SCOREPRED] = KFORDPREDICT (CVSVMMODEL) ؛outlierrate = میانگین (نمره دار<0)
Outlierrate = 0. 0467
با استفاده از SVM باینری چندین مرز کلاس پیدا کنید
یک طرح پراکنده از مجموعه داده های Fisheriris ایجاد کنید. مختصات یک شبکه را در طرح به عنوان مشاهدات جدید از توزیع مجموعه داده ها درمان کنید و با اختصاص مختصات به یکی از سه کلاس در مجموعه داده ، مرزهای کلاس را پیدا کنید.
مجموعه داده های عنبیه فیشر را بارگیری کنید. از طول و عرض گلبرگ به عنوان پیش بینی کننده استفاده کنید.
بارماهیچهx = اندازه گیری (: ، 3: 4) ؛y = گونه ؛طرح پراکندگی داده ها را بررسی کنید.
شکل gscatter (x (: ، 1) ، x (: ، 2) ، y) ؛H = GCA ؛lims = [H. Xlim H. Ylim] ؛محدودیت های محور x و y را استخراج کنیدعنوان('') ؛xlabel ("طول گلبرگ (سانتی متر)") ؛ylabel ('عرض گلبرگ (سانتی متر)') ؛افسانه('محل','شمال غربی');
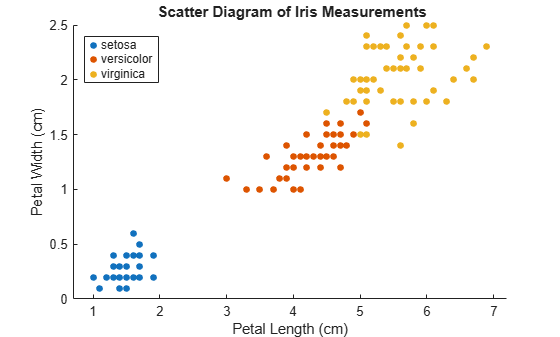
داده ها شامل سه کلاس است که یکی از آنها به صورت خطی از سایرین جدا می شود.
- یک بردار منطقی (indx) ایجاد کنید که نشان می دهد آیا یک مشاهده عضو کلاس است یا خیر.
- یک طبقه بندی کننده SVM را با استفاده از داده های پیش بینی کننده و Indx آموزش دهید.
- طبقه بندی کننده را در سلول یک آرایه سلول ذخیره کنید.
ترتیب کلاس را تعریف کنید.
svmmodels = سلول (3،1) ؛کلاس ها = منحصر به فرد (y) ؛g (1) ؛٪ برای تکرارپذیری برایj = 1: numel (کلاس ها) indx = strcmp (y ، کلاس (j)) ؛٪ برای هر طبقه بندی کلاس های باینری ایجاد کنیدsvmmodels = fitcsvm (x ، indx ،"کلاسهای کلاس"،[غلط درست]،"استاندارد"،درست است، واقعی،. 'Keelfction','RBF',"Boxconstraint"، 1) ؛پایان
Svmmodels یک آرایه سلول 3 به 1 است که هر سلول حاوی طبقه بندی طبقه بندی شده طبقه بندی کننده است. برای هر سلول ، کلاس مثبت به ترتیب Setosa ، Versicolor و Virginica است.
یک شبکه خوب را در طرح تعریف کنید و مختصات را به عنوان مشاهدات جدید از توزیع داده های آموزشی درمان کنید. نمره مشاهدات جدید را با استفاده از هر طبقه بندی تخمین بزنید.
D = 0. 02 ؛[x1grid ، x2grid] = meshgrid (min (x (: ، 1)): d: max (x (: ، 1)) ،.min (x (: ، 2)): d: max (x (: ، 2))) ؛xgrid = [x1grid (:) ، x2grid (:)] ؛n = اندازه (xgrid ، 1) ؛نمرات = صفر (n ، numel (کلاس)) ؛برایj = 1: numel (کلاس ها) [~، امتیاز] = پیش بینی (svmmodels ، xgrid) ؛نمرات (: ، j) = نمره (: ، 2) ؛٪ ستون دوم حاوی نمرات کلاس مثبت است پایان
هر ردیف نمرات شامل سه امتیاز است. شاخص عنصر با بیشترین امتیاز ، شاخص کلاس است که مشاهده کلاس جدید به احتمال زیاد به آن تعلق دارد.
هر مشاهده جدید را با طبقه بندی کننده مرتبط کنید که حداکثر نمره را به آن می دهد.
[~، maxscore] = حداکثر (نمرات ، [] ، 2) ؛
رنگ در مناطق طرح بر اساس کلاس که مشاهده جدید مربوط به آن تعلق دارد.
شکل H (1: 3) = gscatter (xgrid (: ، 1) ، xgrid (: ، 2) ، maxscore ،.[0. 1 0. 5 0. 5 ؛0. 5 0. 1 0. 5 ؛0. 5 0. 5 0. 1]) ؛نگه داشتنonH (4: 6) = gscatter (x (: ، 1) ، x (: ، 2) ، y) ؛عنوان('') ؛xlabel ("طول گلبرگ (سانتی متر)") ؛ylabel ('عرض گلبرگ (سانتی متر)') ؛افسانه (ح ، منطقه ستوسا ","منطقه مارپیچ","منطقه ویرجینیکا",. 'مشاهده شده setosa',"مشاهده شده Versicolor","مشاهده شده ویرجینیکا">,. 'محل','شمال غربی') ؛محورتنگنگه داشتناز روی
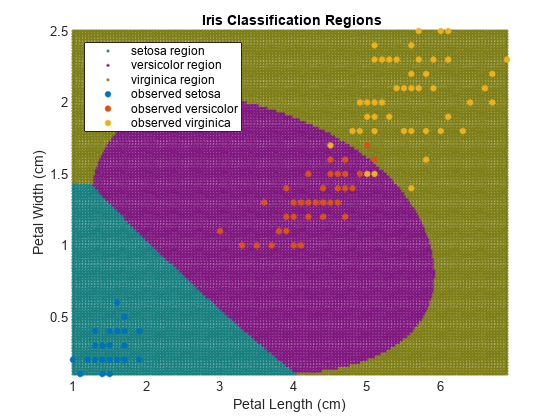
طبقه بندی SVM را بهینه کنید
HyperParameters را به طور خودکار با استفاده از FITCSVM بهینه کنید.
مجموعه داده های یونوسفر را بارگیری کنید.
باریون کرهHyperParameters را پیدا کنید که با استفاده از بهینه سازی خودکار HyperParameter ، از دست دادن اعتبار متقابل پنج برابر به حداقل می رسد. برای تکرارپذیری ، بذر تصادفی را تنظیم کرده و از عملکرد "پیش بینی-بهبود-به علاوه" استفاده کنید.
رفیقپیش فرضmdl = fitcsvm (x ، y ،"OptimizeHyperParameters",'خودکار', . "HyperparameteroptimizationOptions"، ساختار ("AcquisitionFunctionName", . "انتظار می رود-به علاوه"))
| ===================================================================================================================================================.===========================================================================================================================================.== ||iter |EVAL |هدف |هدف |پرفروش |پرفروش |BoxConstraint |Keelscale |||نتیجه ||زمان اجرا |(مشاهده شده) |(برآورد.) |||| ===================================================================================================================================================.===========================================================================================================================================.== ||1 |بهترین |0. 25926 |17. 077 |0. 25926 |0. 25926 |64. 836 |0. 0015729 ||2 |قبول |0. 35897 |0. 13345 |0. 25926 |0. 26547 |0. 036335 |5. 5755 ||3 |بهترین |0. 13105 |6. 753 |0. 13105 |0. 14588 |0. 0022147 |0. 0023957 ||4 |قبول |0. 35897 |0. 30037 |0. 13105 |0. 13108 |5. 1259 |98. 62 ||5 |قبول |0. 1339 |13. 532 |0. 13105 |0. 1311 |0. 0011147 |0. 0010089 ||6 |قبول |0. 13105 |5. 8637 |0. 13105 |0. 13106 |0. 0010151 |0. 0045756 ||7 |بهترین |0. 12821 |8. 1495 |0. 12821 |0. 12824 |0. 0010563 |0. 0022307 ||8 |قبول |0. 1339 |11. 148 |0. 12821 |0. 13025 |0. 0010113 |0. 0026572 ||9 |قبول |0. 12821 |5. 945 |0. 12821 |0. 12981 |0. 0010934 |0. 0022461 ||10 |قبول |0. 12821 |7. 3526 |0. 12821 |0. 12951 |0. 0010315 |0. 0023551 ||11 |قبول |0. 13675 |14. 433 |0. 12821 |0. 13003 |965. 35 |0. 41142 ||12 |قبول |0. 35897 |0. 3372 |0. 12821 |0. 12951 |468. 37 |750. 25 ||13 |قبول |0. 19088 |16. 942 |0. 12821 |0. 12949 |967. 14 |0. 10698 ||14 |قبول |0. 1339 |5. 5745 |0. 12821 |0. 12952 |987. 97 |1. 509 ||15 |قبول |0. 12821 |6. 1568 |0. 12821 |0. 12953 |152. 54 |0. 66927 ||16 |قبول |0. 1339 |1. 1105 |0. 12821 |0. 12969 |0. 079463 |0. 02889 ||17 |قبول |0. 12821 |2. 8495 |0. 12821 |0. 12979 |0. 019736 |0. 0093692 ||18 |قبول |0. 14245 |0. 416 |0. 12821 |0. 12966 |0. 006421 |0. 017524 ||19 |قبول |0. 1339 |9. 5366 |0. 12821 |0. 12966 |0. 13148 |0. 01135 ||20 |قبول |0. 12821 |2. 1941 |0. 12821 |0. 12969 |4. 7977 |0. 16025 || ===================================================================================================================================================.===========================================================================================================================================.== ||iter |EVAL |هدف |هدف |پرفروش |پرفروش |BoxConstraint |Keelscale |||نتیجه ||زمان اجرا |(مشاهده شده) |(برآورد.) |||| ===================================================================================================================================================.===========================================================================================================================================.== ||21 |قبول |0. 12821 |3. 7125 |0. 12821 |0. 12969 |33. 166 |0. 3481 ||22 |قبول |0. 1339 |5. 9165 |0. 12821 |0. 12953 |0. 0092066 |0. 0044777 ||23 |قبول |0. 12821 |5. 3915 |0. 12821 |0. 12954 |1. 4193 |0. 069246 ||24 |قبول |0. 1339 |6. 3038 |0. 12821 |0. 12959 |202. 78 |0
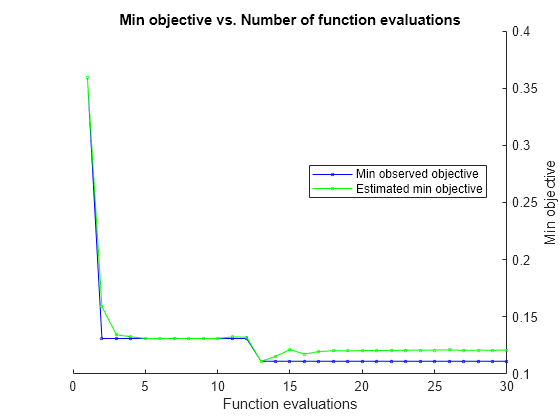

60371 ||25 |قبول |0. 13105 |1. 4095 |0. 12821 |0. 12959 |2. 9285 |0. 13117 ||26 |قبول |0. 12821 |3. 3673 |0. 12821 |0. 12957 |17. 832 |0. 26308 ||27 |قبول |0. 12821 |4. 2805 |0. 12821 |0. 1285 |15. 37 |0. 23218 ||28 |قبول |0. 12821 |3. 347 |0. 12821 |0. 1284 |14. 943 |0. 24095 ||29 |قبول |0. 13105 |6. 4018 |0. 12821 |0. 12839 |0. 75691 |0. 043713 ||30 |قبول |0. 12821 |2. 0967 |0. 12821 |0. 12833 |14. 652 |0. 27296 |
________________________________________________________________ بهینه سازی انجام شد. MaxObjectiveEvaluations از 30 رسیده است. کل ارزیابی های تابع: 30 کل زمان سپری شده: 205. 015 ثانیه کل زمان ارزیابی تابع هدف: 178. 0324 بهترین نقطه عملی مشاهده شده: BoxConstraint KeelScale _____________ ___________ 0. 0010562 Essential2 تابع هدف 2 = 0. 0010562 Objective200. مقدار تابع = 0. 12958 زمان ارزیابی عملکرد = 8. 1495 بهترین نقطه ممکن تخمین زده شده(طبق مدل ها): BoxConstraint KeelScale _____________ ___________ 17. 832 0. 26308 مقدار تابع هدف تخمینی = 0. 12833 زمان ارزیابی تابع = 3. 2181تجارت با گزینههای باینری...

ما را در سایت تجارت با گزینههای باینری دنبال می کنید
برچسب :
نویسنده : نازنین فراهانی
بازدید : 29
